记在前面
今天用到redis缓存过期时间,突然想到之前面试时问到缓存击穿问题。当时给的解决方案只是曲线救国罢了,在此记录一下:
缓存击穿
应用中有一些访问量很高的热点数据,我们一般会将其放在缓存中以提高访问速度。另外,为了保持时效性,我们通常还会设置一个过期时间。设置了过期时间的cache,在它过期那一刻,海量的请求会直连DB,DB负载过重问题,甚至导致数据库崩溃。
记得当时我给的解决方案是异步起任务定时刷新缓存,相当于是不让缓存过期。这个方案其实解决不了全部问题,缓存击穿发生时刻是在缓存KEY的过期瞬间。现在常用的解决方式有如下两种:互斥锁、永远不过期
互斥锁
互斥锁指的是在缓存KEY过期去更新的时候,先让程序去获取锁,只有获取到锁的线程才有资格去更新缓存KEY。其他没有获取到锁的线程则休眠片刻之后再次去获取最新的缓存数据。
通过这种方式,同一时刻永远只有一个线程会去读取数据库,这样也就避免了海量数据库请求对于数据库的冲击。
而对于上面说到的锁,我们可以使用缓存提供的一些原子操作来完成。对于 redis 缓存来说,我们可以使用其 SETNX 命令来完成。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public String get(key) {
String value = redis.get(key);
if (value == null) { // 缓存过期
// 设置1分钟的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 1 * 60) == 1) { // 代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { // 这个时候代表同时候的其他线程已经load db并回设到缓存了,
// 这时候重试获取缓存值即可
sleep(50);
this.get(key); // 重试
}
} else { // 缓存未过期
return value;
}
}
上面的 key_mutex 其实就是一个普通的 KEY-VALUE 值,我们使用 setnx 命令去设置其值为 1。如果这时候已经有人在更新缓存KEY了,那么 setnx 命令会返回 0,表示设置失败。
上面的互斥锁整体思路是没有问题的,但有有一个细节问题需要处理:有时发生缓存穿透可能是redis缓存服务宕掉造成的,使用了递归,所以有死循环的风险,所以还应该加一个最大重试次数(递归深度)的限制
永不过期
从缓存的角度来看,如果你设置了永远不过期,那么就不会有海量请求数据库的情形出现。此时我们一般通过新起一个线程的方式去定时将数据库中的数据更新到缓存中,更加成熟的方式是通过定时任务去同步缓存和数据库的数据。
但这种方案会出现数据的延迟问题,也就是线程读取到的数据并不是最新的数据。但对于一般的互联网功能来说,些许的延迟还是能接受的。
缓存穿透
与缓存穿透有另外两个缓存问题:缓存穿透和缓存雪崩
缓存穿透是指查询一个一定不存在的数据,因为这个数据不存在,所以永远不会被缓存,所以每次请求都会去请求数据库。如果某些心怀不轨的人利用这个存在的漏洞去伪造大量的请求,那么很可能导致DB承受不了那么大的流量就挂掉了。
对于缓存穿透,有几种解决方案,一种是事前预防,一种是事后预防。
事前预防
就是对所有请求都进行参数校验,把绝大多数非法的请求抵挡在最外层。例如对于获取用户信息的接口,我们可以对用户ID进行参数校验,对于用户ID未负数的请求直接拦截。但即使我们做了全面的参数校验,还是可能存在漏网之鱼,这时候就需要进行事后预防。
事后预防
对于查询结果为空的请求,我们仍然将这个空的结果进行缓存,但是设置一个很短的过期时间(例如一分钟)。在这里我们可以看到,其实我们并没有完全预防非法请求,只不过是将非法请求的风险让承受能力更强的redis去承担,让承受能力稍弱的数据库更安全。
通过上面这两种处理方式,我们基本可以解决缓存穿透的问题。事前预防解决80%的非法请求,剩下的20%非法请求则使用Redis转移风险
布隆过滤器
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
实现原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k。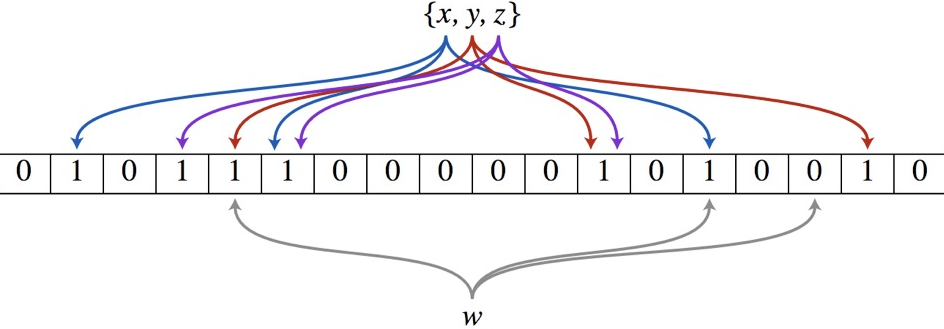
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。
添加元素
对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。
查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到数据库,最终导致数据库瞬时压力过大而崩溃。
缓存雪崩导致的问题一般很难排查,如果没有事先预防,很可能要花很大力气才能找得到原因。对于缓存雪崩的情况,最简单的方案就是在原有失效时间的基础上增加一个随机时间(例如1-5分钟),这样每个缓存过期时间的重复率就会降低,从而减少缓存雪崩的发生。
总结
- 缓存穿透指的是请求不存在的数据,从而使得缓存形同虚设,缓存层被穿透了。缓存雪崩则是指缓存在同一时间同时过期,就像所有雪块同一时刻掉下来,像雪崩一样。缓存击穿则是在某些热点缓存数据过期瞬间发生的。
- 缓存雪崩其实比较好理解,其解决方案也很简单,就是让过期时间变得更加均匀,自然就可以避免这种异常情况的发生。而缓存穿透和缓存击穿则非常相似,但它们还是略有不同。
- 缓存穿透发生的前提是业务上的漏洞,导致出现了非法请求。而缓存击穿只会发生于访问量很大的热点数据,并且是发生在其过期进行更新数据的瞬间。