概要
生产页面请求缓慢,短时不可访问
事件回顾
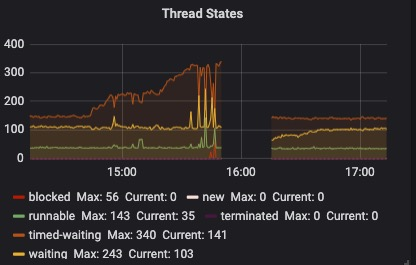
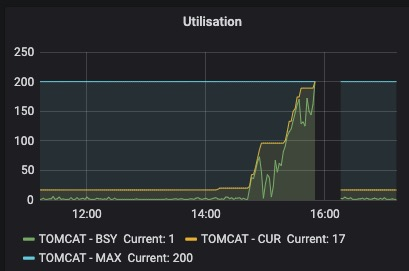
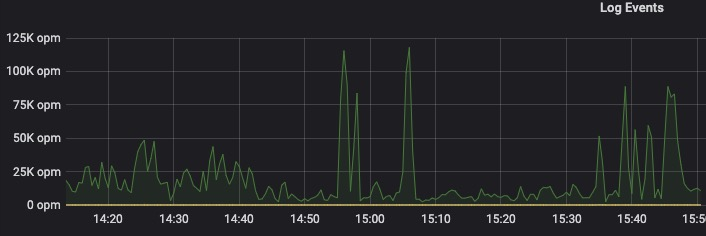
14:40 开始,服务监控报警开始频繁报 接口超时数量 达到阈值。检查服务器负载,发现某台机器核心服务进程负载超高(150%以上), jstack检查java进程, 发现大量线程block在同一段代码AuthUtils.java的180行: 这是一条日志打印。 根据以往经验,感知到这是大量日志导致频繁IO。**
15:30 相关研发开始修改代码,删除该条日志。
15:40 向测试发起了hotfix紧急流程, 开始上线。
16:10 上线过程中,生产出现了小于1分钟的完全不可访问情况。查看监控,新上线机器资源瞬间被耗尽,经过排查,原因是时间持续期间大量的的前端保存了大量的报错日志堆积,服务上线后全部请求到后端,导致资源耗尽。😢
16:15 堆积的请求消费完毕后,服务恢复。
总结教训
日志像水, 能载舟亦能覆舟。
很多情况下,日志对于我们排查问题非常有帮助,但一定注意度的问题。过多的日志能耗死我们的正常服务。😱
限流逻辑
前端对于堆积请求,考虑限流逻辑。
后端考虑限流和降级逻辑。
报警很重要!!
及时响应报警信息, 尤其是超时,GC等。